


How to design a B2B API integration
Deep dive into real-world API integrations and how to build them

Hey, I’m Colin! I help PMs and business leaders improve their technical skills through real-world case studies. For more, check out my Live cohort course and subscribe on Substack.
One of the most common features for B2B SaaS products are integrations with other SaaS products. It’s so common that it’s created a whole new class of products like Merge and Mulesoft.
Let’s dive into how you can successfully build an external API integration from scratch.
Scenario
Your company, DentScheduler, builds scheduling software for dental offices. Your customers have been asking to sync appointments with a popular electronic health records system called HealthFlow. When a patient schedules an appointment in your system, they want that patient's information and appointment details to automatically appear in HealthFlow, saving their staff from double data entry and reducing mistakes.
Reliability & Data Consistency
Our system needs to handle the critical nature of healthcare appointments flawlessly. When a sync fails, it must automatically retry without creating duplicates, and we can never allow partial syncs that might separate patient data from their appointments. This is foundational for maintaining trust with dental practices.
Performance & Scalability
Dental practices need near-immediate confirmation that appointments are synced, ideally within 30 seconds. The system must be particularly robust during high-traffic periods like Monday mornings, when booking volumes can spike to 5x normal levels. A typical practice might have 50-200 appointments scheduled daily per location. It needs to work within HealthFlow's rate limits while supporting data backfills for new customers who bring historical records.
High Level Design
Let’s start with the functional requirements and extend our design to handle scalability later.
In our workflow, a patient will log in to DentScheduler and book an appointment. Once the appointment is created in HealthFlow, we’ll confirm with the patient.
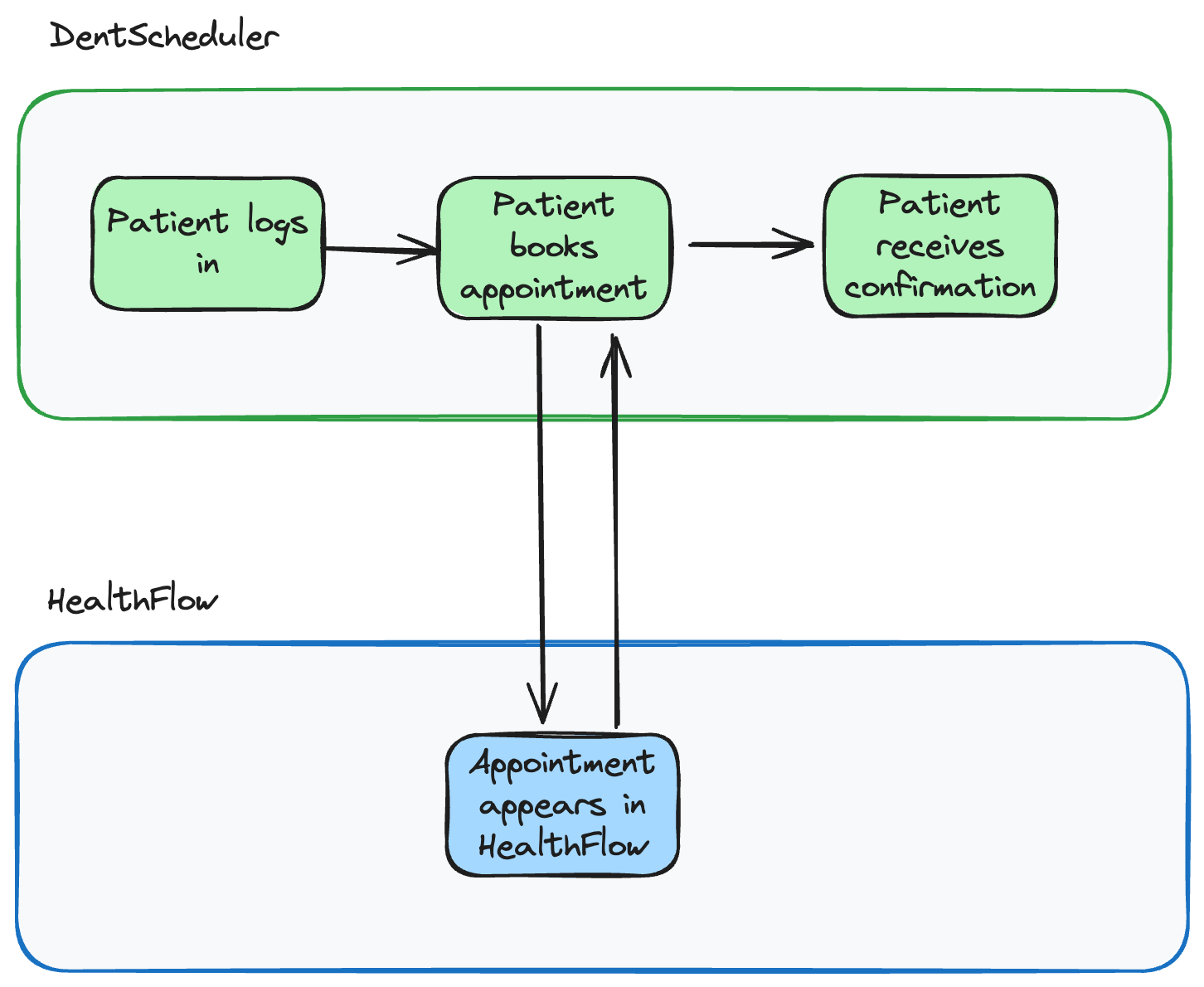
When syncing an appointment, we’ll need to:
Create a patient record if one doesn’t already exist
Create a new appointment
HealthFlow supports these actions through the /appointment and /patient API endpoints.

Based on the supported API endpoints, we can:
Get a list of all appointments (GET /appointments)
Create a new appointment (POST /appointments)
Get the details for a specific appointment by ID (GET /appointments/{id})
Update a specific appointment by ID (PUT /appointments/{id})
Get a list of all patients (GET /patients)
Create a new patient (POST /patients)
Look up a patient with identifiers (POST /patients/search)
Get the details for a specific patient by ID (GET /patient/{id})
Update a specific patient by ID (PUT /patient/{id})
Here’s what our high-level architecture will look like:
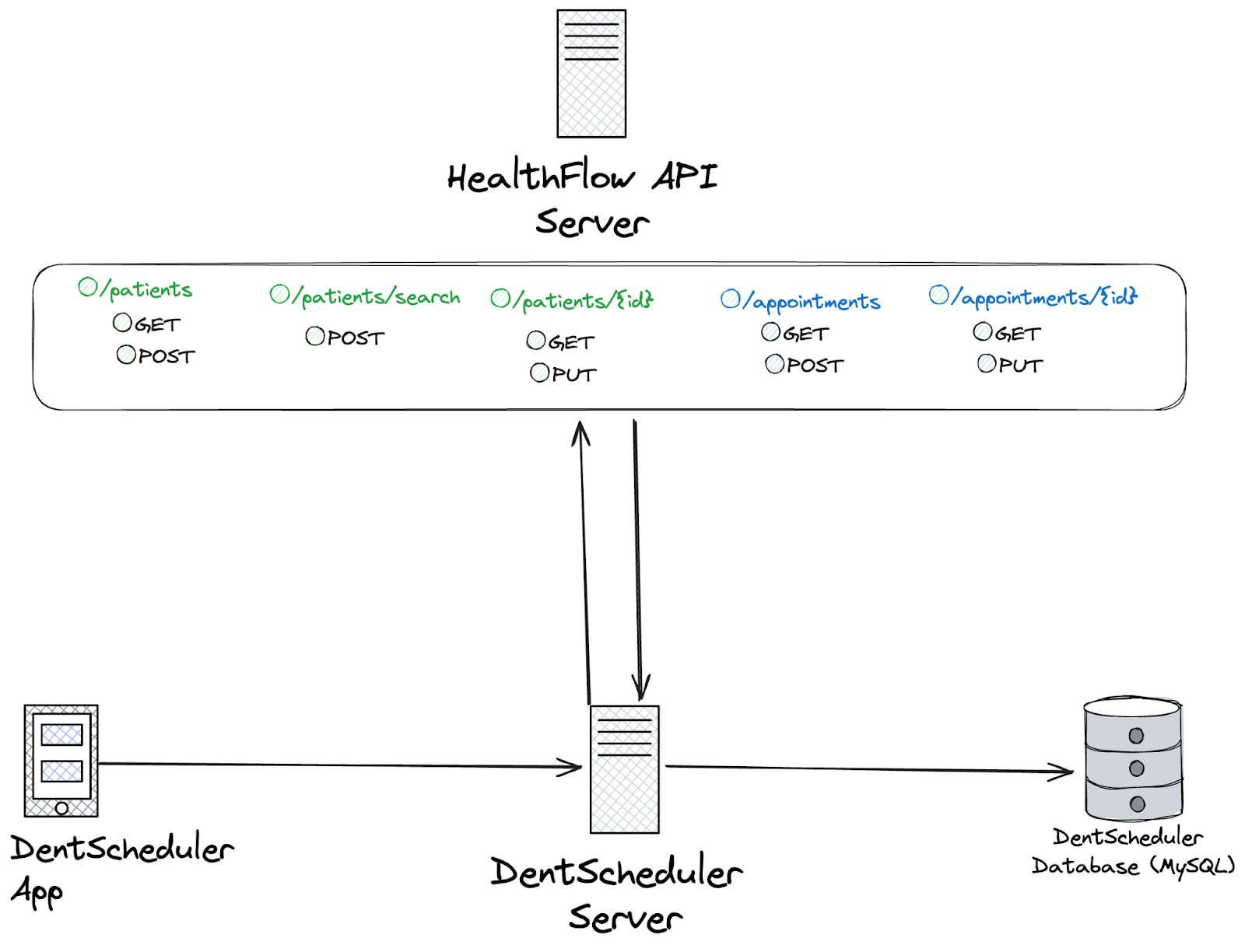
Based on our user workflow, this integration will require us to only create patients if the patient doesn’t already exist in HealthFlow and push over any appointment details.
Now we’re ready to walk through our integration workflows. We have a few possible scenarios:
The patient already exists in HealthFlow and is known in DentScheduler
The patient already exists in HealthFlow and is not known in DentScheduler
The patient does not exist in HealthFlow
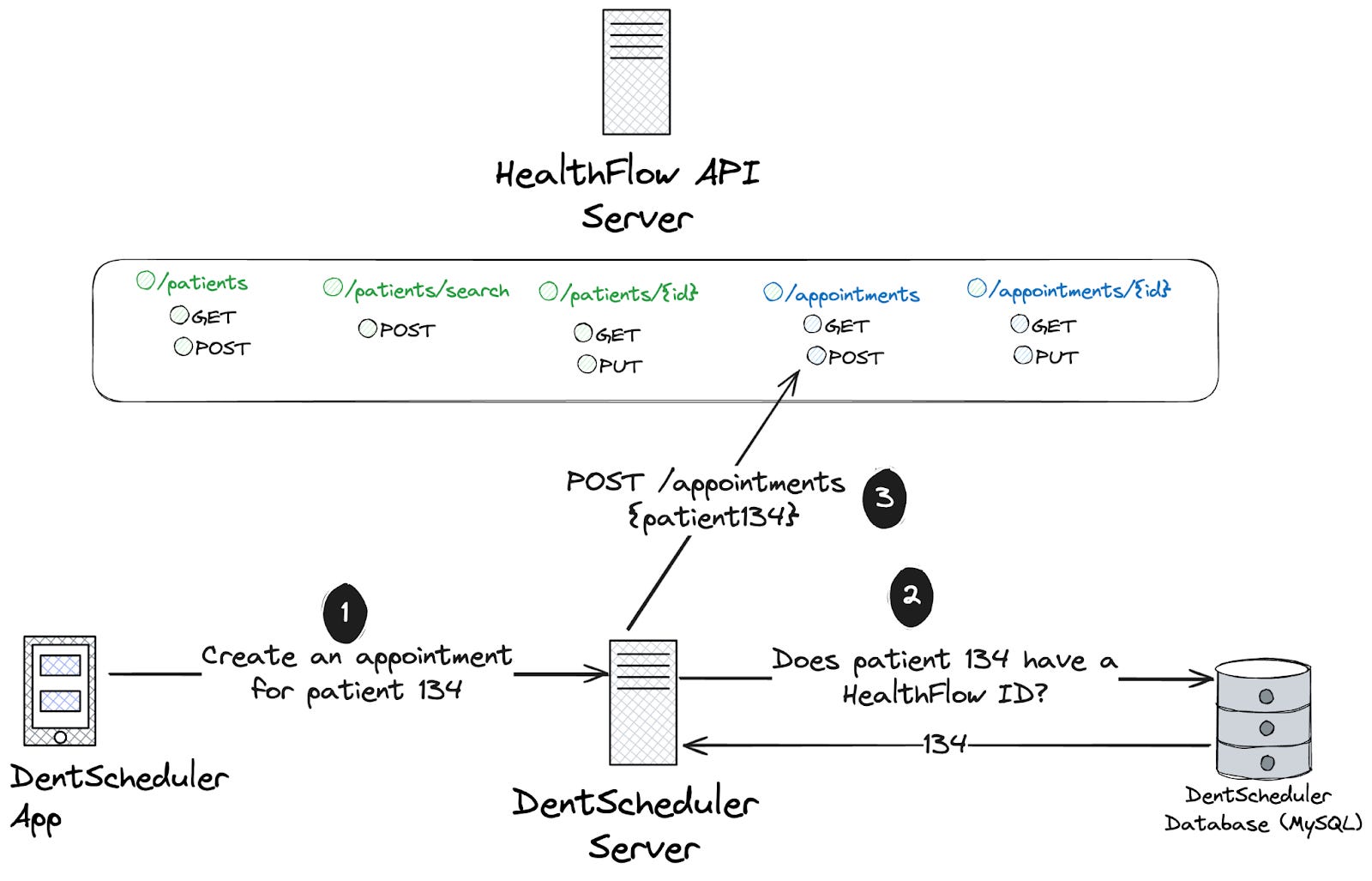
The patient already exists in HealthFlow and is known in DentScheduler
This workflow is used when a patient has previously used DentScheduler to book an appointment that was synced to HealthFlow. This is the easiest workflow as we already have the patient’s HealthFlow id.
To sync our appointment, we’ll need to:
Receive the new appointment request in DentScheduler from our front end application
Fetch the patient’s HealthFlow id from our database
Send a POST request to /appointments with the appointment details, referencing the patient’s HealthFlow ID
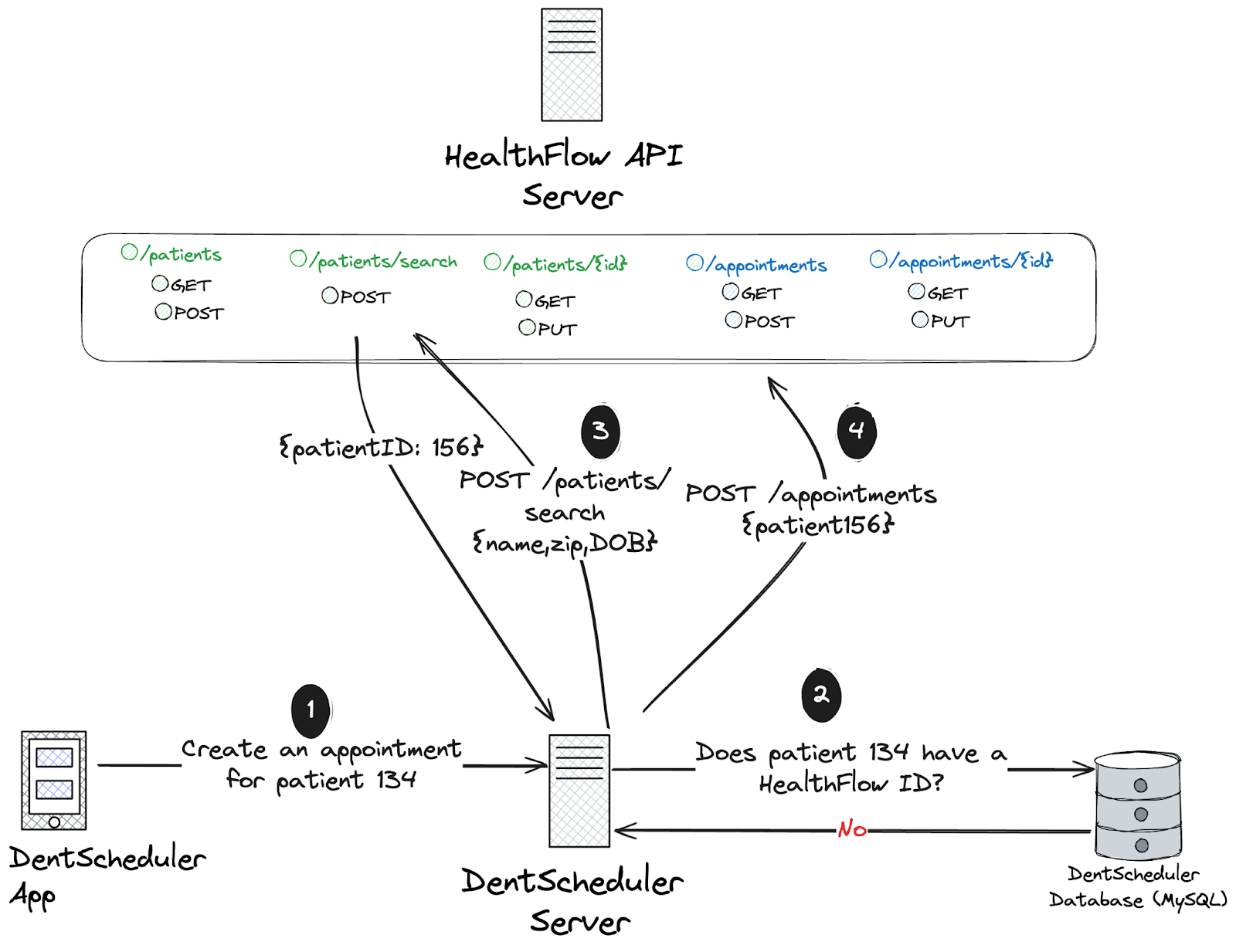
The patient already exists in HealthFlow and is not known in DentScheduler
This case is a bit more complex. If we don’t have an existing HealthFlow id for the patient, this is likely the first time we’re performing the sync. This means the patient may or may not already exist in HealthFlow.
Receive the new appointment request in DentScheduler from our front end application
Fetch the patient’s HealthFlow id from our database (no id found)
Send a POST request to /patients/search with patient identifiers like name, zip, and date of birth to look up the patient
Patient is found and patientID 156 is returned by HealthFlow
Send a POST request to /appointments with the appointment details, referencing the patient’s HealthFlow ID
The patient does not exist in HealthFlow
Our final case has one additional step. When we’re unable to find the patient with a search, we assume the patient does not exist and create a new one. We then create the corresponding appointment for the patient.
Receive the new appointment request in DentScheduler from our front end application
Fetch the patient’s HealthFlow id from our database (no id found)
Send a POST request to /patients/search with patient identifiers like name, zip, and date of birth to look up the patient (no id found)
Send a POST request to /patients/ with patient details to create a new patient (patientID 187)
Send a POST request to /appointments with the appointment details, referencing the patient’s HealthFlow ID

Now we’ve covered the basic integration patterns for appointment syncing with HealthFlow. But what about all of the performance requirements?
Design Deep Dive
Recapping the performance requirements, we need:
Failed syncs to be retried automatically (dentists can't miss appointments)
System must handle HealthFlow API downtime without losing sync data
Appointments must never be duplicated in HealthFlow even if our system retries
System must handle burst traffic (Monday mornings typically have 5x normal booking volume)
Must handle practices scheduling 50-200 appointments per day per location
Must support HealthFlow's API rate limits and quotas
Need mechanism to backfill historical data for new customers
These look like a lot of complex requirements, but we can handle many of them with a single solution.
Queues
Ensuring that all transactions complete successfully is critical to this integration. To address concerns with API downtime, retries, burst traffic, and rate limits, we’ll implement a queue.
The queue will store requests from DentScheduler to HealthFlow before they’re sent out. If the request is successful, we’ll remove it from the queue. Otherwise, we’ll keep it in the queue and try again. This is a simple and commonly used method to improve the durability of external integrations.

Scaling
In our updated architecture, we have a single worker that pulls messages out of the queue and sends them to HealthFlow. Although this architecture is more robust than the previous one, we haven’t improved the scale at all.
Let’s take advantage of our queue by horizontally scaling our workers – this will increase our throughput with the external API.
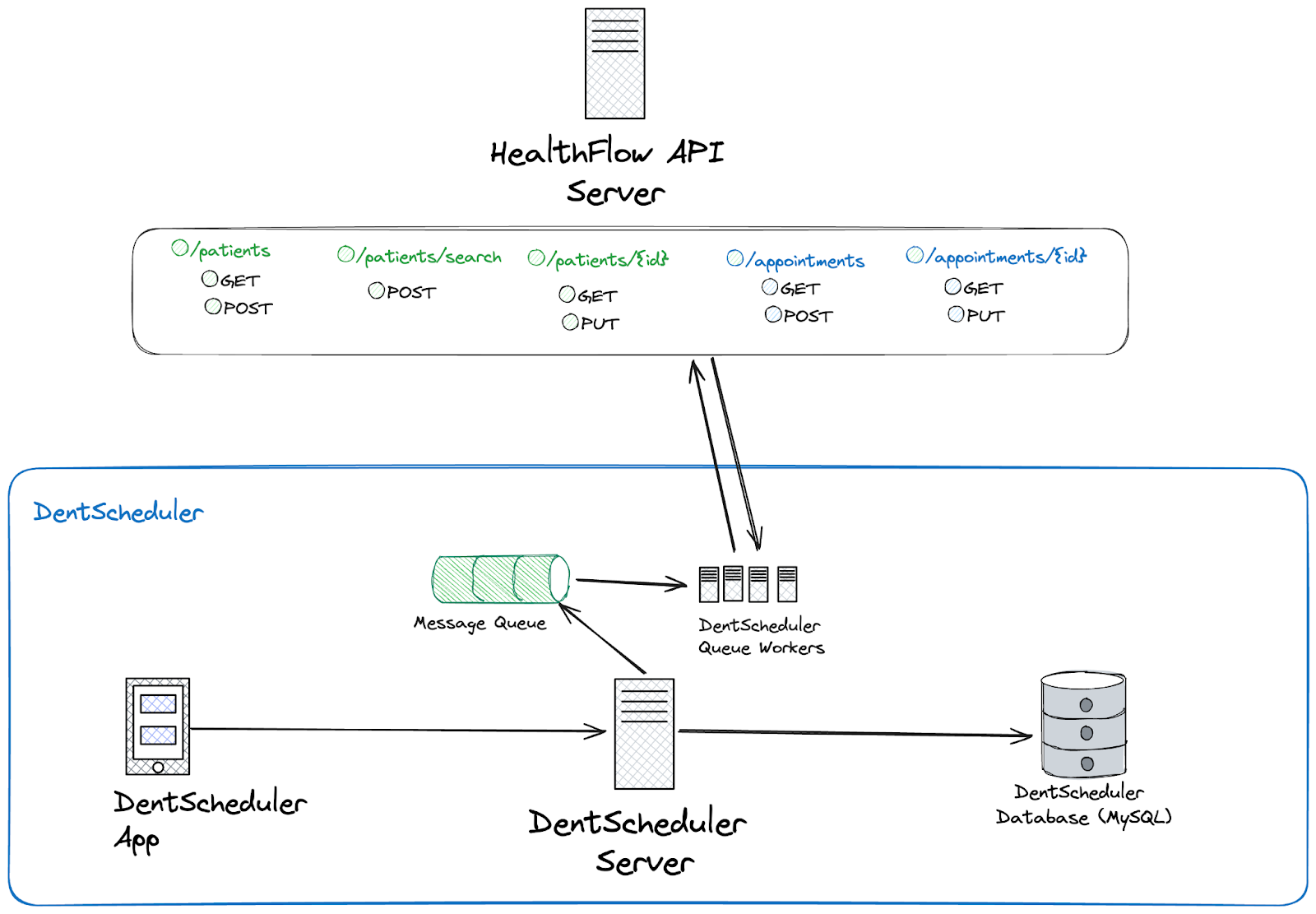
Now that we’ve scaled to multiple servers, we’ll be able to easily handle our 5x spike in volume on Mondays without slowing down the sync. We can also use this design pattern to help speed up data backfilling for new customers. It would be a good idea to handle backfills overnight as appointment bookings drop off dramatically during that time.
Unfortunately, adding multiple servers introduced a new issue – we now can’t track how many requests we’re making across all servers and risk exceeding the rate limit. We could handle this by simply allowing requests to fail and retry from the queue, or we could implement an external counter that can be used by all workers.
Risks
Although this architecture is much better than direct API calls, there are still some risks.
If HealthFlow rejects a patient creation but accepts the appointment, we could end up with orphaned appointments. Our queue system needs careful transaction management.
Additionally, patient matching across systems is complex. Names and dates might be formatted differently or contain typos, leading to potential duplicate records. Data quality will need to be monitored by both teams to ensure matching is working as expected.
Review & Why it Matters
Understanding integration architecture changes how product managers serve their customers and work with their teams. What looks like a simple "sync appointments" feature actually requires careful consideration of reliability, scalability, and error handling. Without this knowledge, it's easy to underestimate development time or overpromise capabilities to customers.
Understanding the technical foundations of API integrations helps PMs make better real-world decisions. Instead of asking "can we sync with HealthFlow?", they can discuss meaningful tradeoffs about sync timing, error handling, and development priorities. They can explain to customers why queuing matters for reliability, or why "instant" sync might not be the best solution.
Most importantly, this knowledge builds trust – both with engineering teams who appreciate a PM who understands the complexity of their work, and with customers who benefit from realistic expectations and robust solutions. Good integrations aren't just features, they're critical business capabilities that deserve thoughtful product management.