


How software gets shipped
End-to-end guide to shipping a new feature

Hey, I’m Colin! I help PMs and business leaders improve their technical skills through real-world case studies. For more, check out my Live cohort course and subscribe on Substack.
You’ve probably heard of terms like pull request, commits, and CI/CD, but what do they actually mean? Today, let’s explore how software gets shipped.
How internet software works
As a quick reminder, all internet software products follow the same core patterns. They have 3 main components:
Client – what your users interact with. Eg: website, mobile, tesla, smart fridge
Server – processes requests to fetch and store data or perform actions, like syncing your google calendar
Database - permanent storage of data

When we ship new software, we are updating one or more of these three components.
Writing Code
The first step in building your product is writing code. Code seems intimidating, but it’s really just a collection of text files.

You’ll need code for both your client and server. When engineers write code, they sync it to external storage so it doesn’t get lost or overwritten. This is like syncing your files to Dropbox or Google Drive. We call this external storage a repository. Think of a repository as a shared folder that tracks every change made to its contents.

GitHub, Bitbucket, and GitLab are common cloud software products that provide repositories.
Each repository contains many text files that, when used together, run your entire product. Common patterns for repositories include:
Polyrepo: Separate repositories for your client and server code
Monorepo: One repository for your whole product
Engineers will write code for different parts of the product at the same time and collaborate through repositories. This is similar to many people editing a Google Doc at the same time.
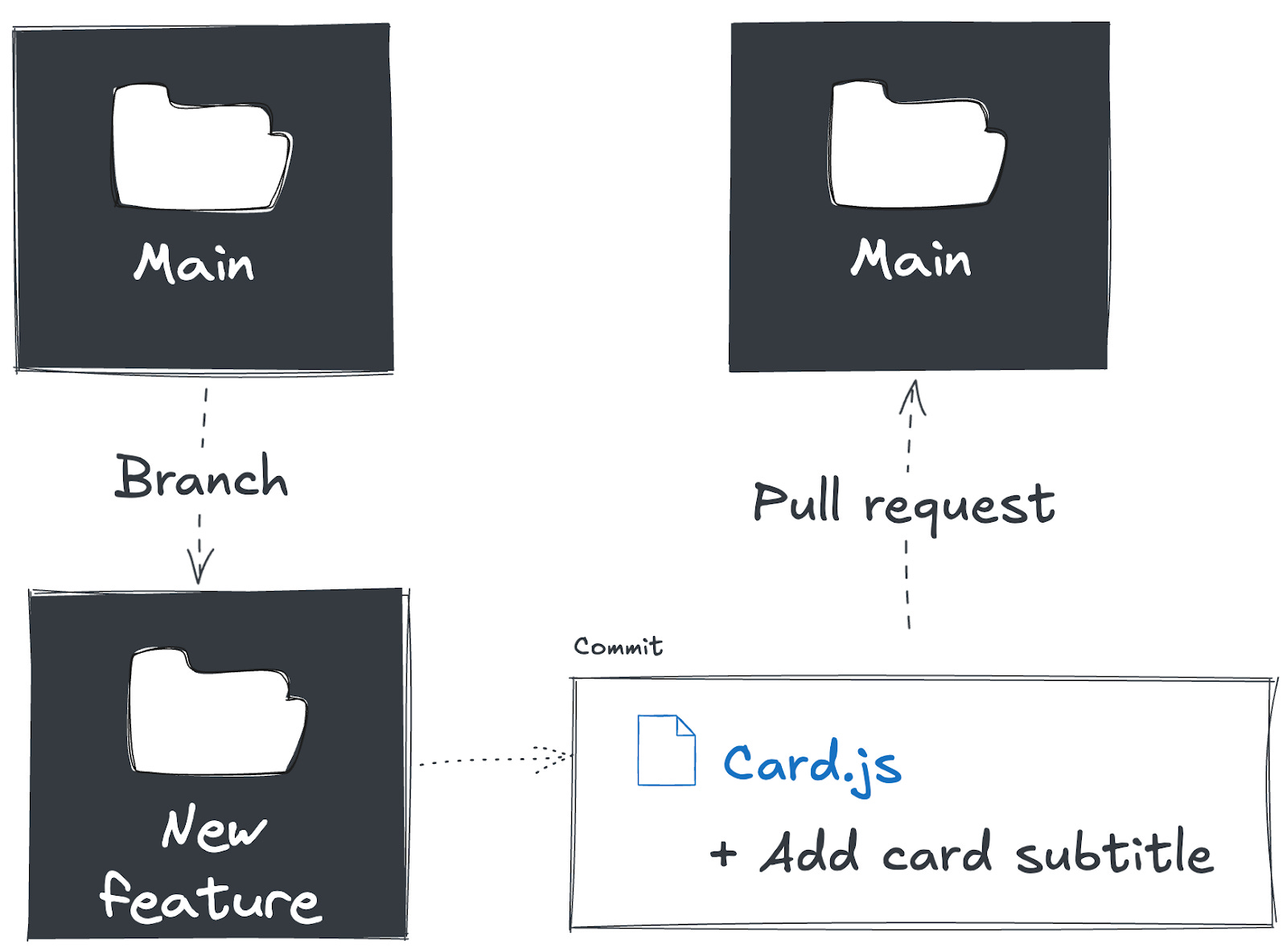
To make a change, an engineer will first create a temporary copy of the whole repository. This is called a branch. Creating a branch allows the engineer to make modifications without changing the main repository files.
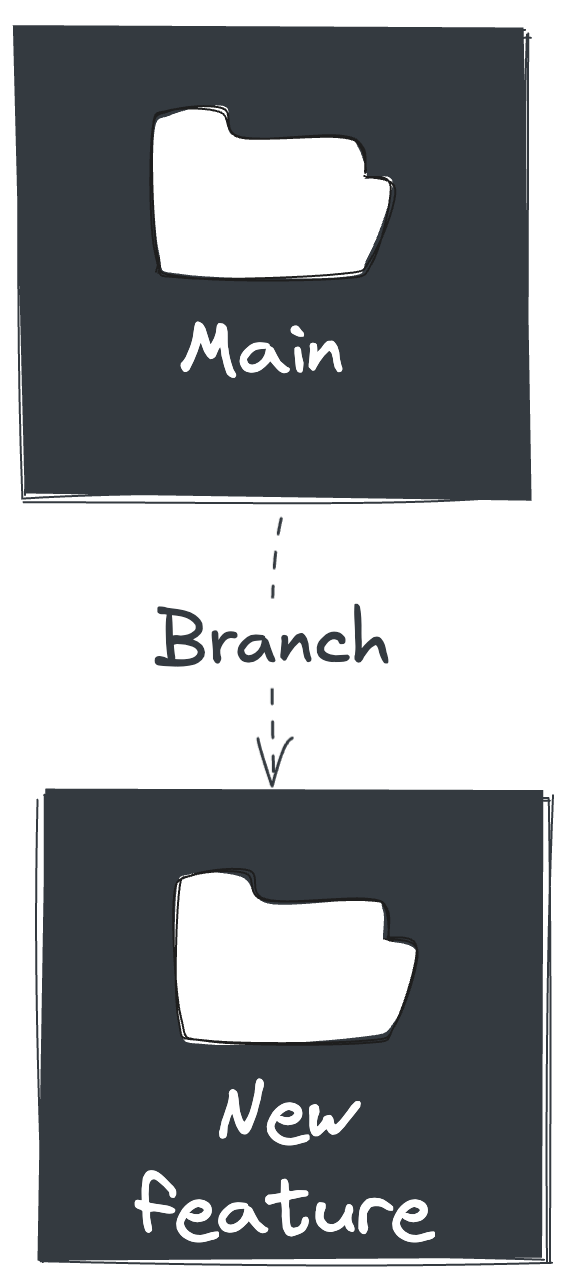
Once the branch is created, an engineer can begin making changes. Each change they make to a text file is tracked. When they want to store those changes, they create a commit. A commit contains the collection of text file changes made since the last commit.

Eventually, the engineer will be done writing their code and will want to publish their code back into the main repository. They will create a pull request to indicate to other engineers that their work is ready for review. A pull request collects all of their commits and lets other engineers provide feedback.
Once everyone agrees the new code is ready, it can be deployed.
Deploying Code
Deploying code is how we get the updated code from the repository over to our users. Again, this could be on the client, server, or both.
Our products have different environments. An environment is the collection of code that represents the current state of the product.
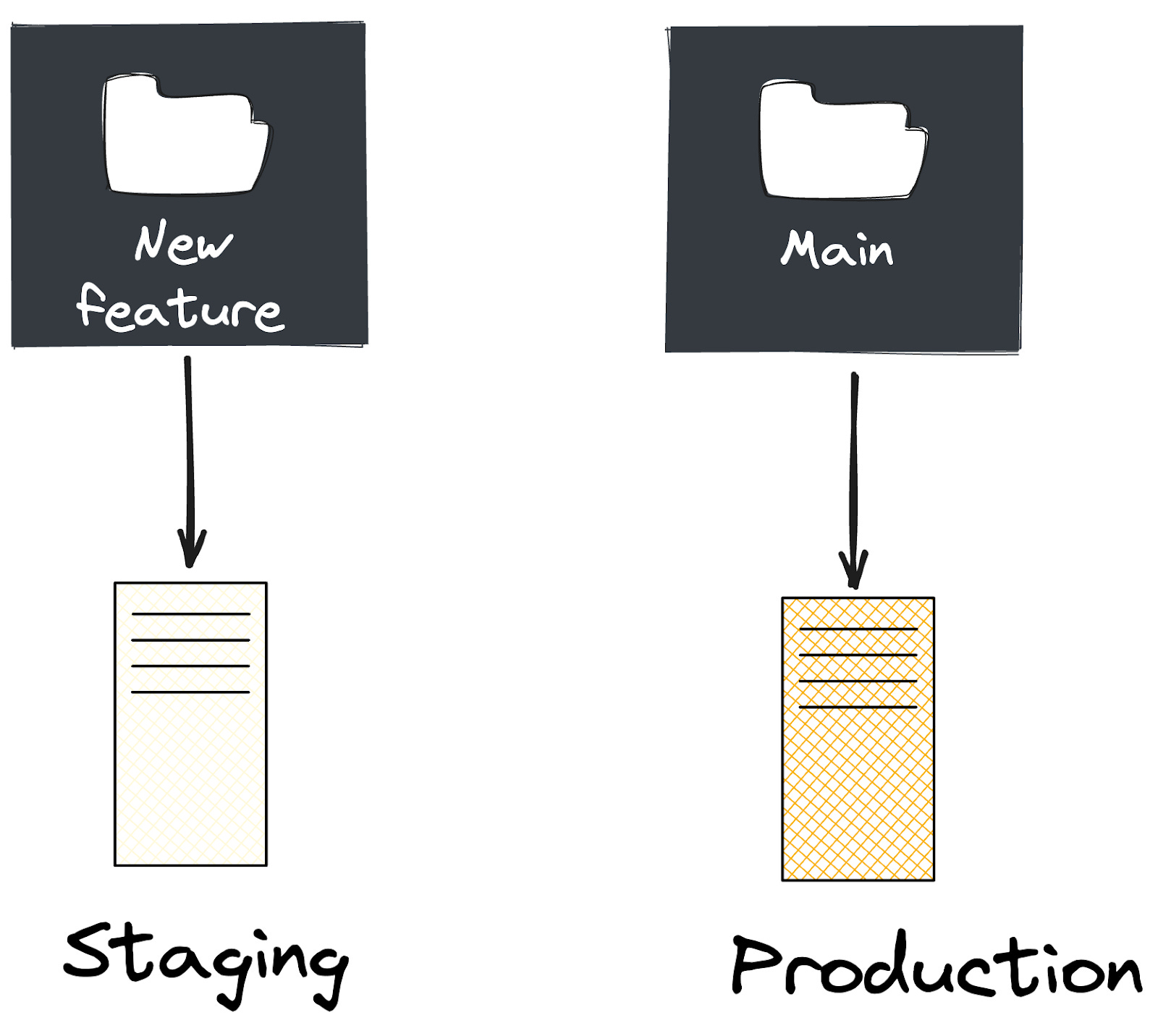
It’s common to have a production environment that users access and a few lower environments for internal use, such as QA, staging, dev, canary, etc. These lower environments usually have code that is less stable than production or unreleased features that need further testing.
To get code from our repository to an environment, we need to deploy it. Deployment is the process of copying files from our repository to a client or server environment so we can run our new code. For instance, developers might test new features in a 'dev' environment before moving them to 'staging' for final testing, and finally to 'production' where real users access them
There are two common deployment methodologies:
Scheduled releases
Continuous deployment
Scheduled releases are exactly what they sound like – every month, you collect all of the approved changes and push them on to your production server. Usually there is a testing process on a QA or Staging server prior to production deployment.
Continuous deployment automates the process of deployment. Instead of pushing changes once a month, you push every change as soon as it’s approved. Continuous deployment is often paired with Continuous Integration – a process of running automated tests on every change. If any test fails, the new code will not be deployed.
Testing
If you want to deploy quality code, you’ll need to test it.
Three common types of testing include:
Unit tests
Integration tests
End-to-end tests
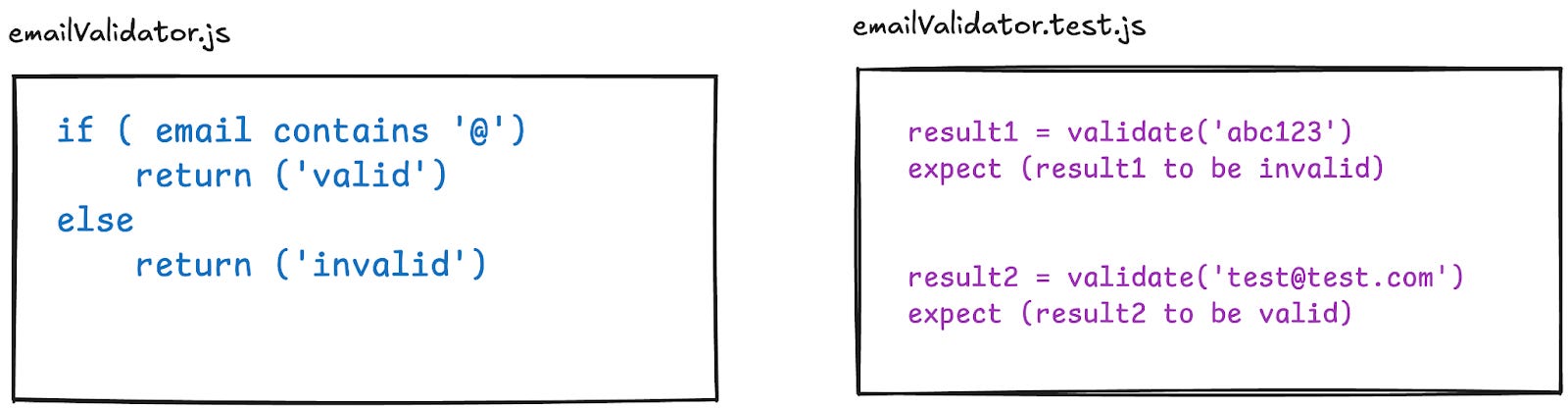
Unit tests are actually code. After an engineer writes code for a new feature, they will write more code that tries to automatically use that feature with expected inputs and outputs. Writing unit tests helps engineers ensure they don’t break something accidentally later if they are updating the feature.
Integration tests are tests between parts of your system. For example, you could run an integration test for your login flow between your client and server. Integration tests are often done manually but can be automated through tools like Selenium.
Finally we have end-to-end tests. These require you to write out each step in the user’s workflow and ensure everything performs as expected. E2E tests include downstream systems, like billing and reporting. End-to-end testing is a great idea for larger features or complex, interdependent systems.

Putting it all together
Understanding how software gets shipped can improve your communication with engineers and improve the quality of your product. The process flows from writing code in repositories, through thorough testing across different types of tests, to deploying in various environments using either scheduled releases or continuous deployment.
Consider getting more involved with testing if you have challenges with users complaining about quality or bugs!